深入ethereum源码-从区块头看共识挖矿
区块是区块链的基本组成单位,而区块头又是区块的核心数据,本文希望从区块头延展开来,看看区块链的挖矿机制。
区块头的基本数据结构
废话不多说,直接看代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
乍一看区块头的字段非常多,别着急,接下来我们逐个分析。按照字段的作用,我们可以将这些字段分成6大类(如代码注释所示),分别控制结构、状态、挖矿等信息,下面我们依次查看.
本文引用源码大部分均位于miner/consensus两个包中,代码引用均会给出文件名
结构信息
1.ParentHash
简单来说,区块链其实是一个单向链表。那么单向链表中必然存在一个将链表串起来的指针,这个指针在区块链里就是ParentHash.每个新挖出来的区块都包含了父区块的hash值,这样我们就可以从当前区块一直溯源到创世区块,创世区块hash值为0x00.
2.UncleHash
类似ParentHash,指向叔区块hash值。
3.Number
用于标记当前区块高度,子区块高度一定是父区块+1.
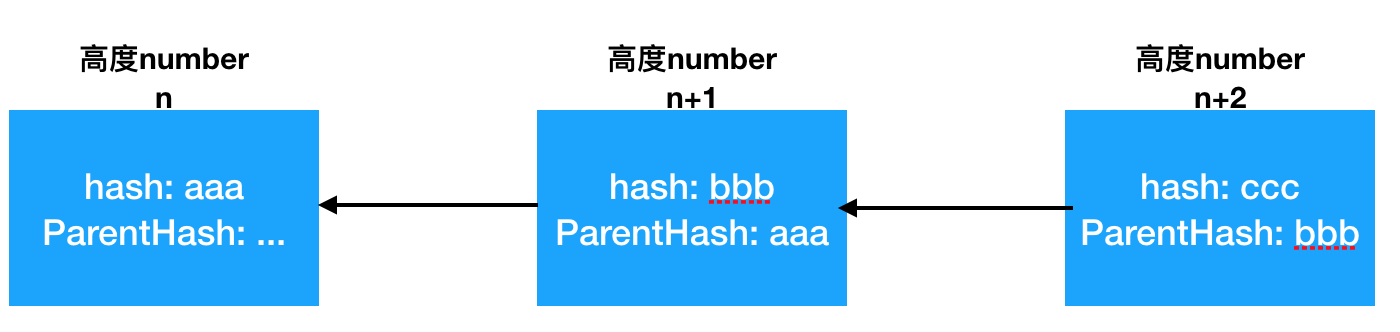
构建区块的代码包含在commitNewWork函数中,该函数其实就是挖矿主流程所在位置。
1 2 3 4 5 6 7 8 9 10 11 12 | |
挖矿基础信息
1.Coinbase
区块链中矿工没挖出一个新区块,都会得到两部分奖励收益:挖矿奖励+手续费,那么这个奖励是到哪个账户的,就是这个coinbase帐号,默认通常是矿工本地第一个账户。
2.GasUsed
实际使用的gas,每执行一笔交易往该字段上累积gas值,具体代码可查看ethereum/go-ethereum/core/state_processor.go:ApplyTransaction.
3.GasLimit
矿工执行交易的上限gas用量,如果执行某个交易时发现gas使用超过这个值则放弃执行后续交易。其数值是基于父区块gas用量来调整,如果parentGasUsed > parentGasLimit * (2/3),则增大该数值,反之则减小。具体实现可参考下面代码实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
状态信息
1.Time
新区块的出块时间(按代码描述,严格来说其实是开始挖矿的时间)。
2.Root,TxHash,ReceiptHash
这三个hash值对验证区块意义重大.
Root代表的区块链当前所有账户的状态,TxHash是本区块所有交易摘要,ReceiptHash是本区块所有收据的摘要。
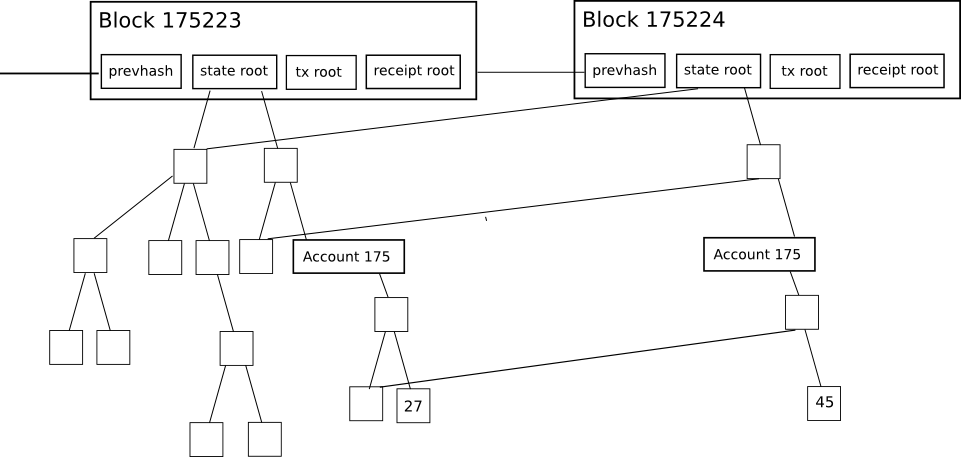
这几个值都是MPT树的root hash值,只要树中任意节点数据有更改,那么这个root hash必然会跟着更改,这就为轻钱包实现提供了可能:不需要下载整个区块的数据,仅使用区块头就可以验证区块的合法性。具体说来,它允许轻客户端轻松地进行并核实以下类型的查询答案:
这笔交易被包含在特定的区块中了么?
-
告诉我这个地址在过去30天中,发出X类型事件的所有实例(例如,一个众筹合约完成了它的目标)
-
目前我的账户余额是多少?
-
这个账户是否存在?
-
假装在这个合约中运行这笔交易,它的输出会是什么?
第一种是由交易树(transaction tree)来处理的;第三和第四种则是由状态树(state tree)负责处理,第二种则由收据树(receipt tree)处理。计算前四个查询任务是相当简单的。服务器简单地找到对象,获取默克尔分支,并通过分支来回复轻客户端。
第五种查询任务同样也是由状态树处理,但它的计算方式会比较复杂。这里,我们需要构建下我们称之为默克尔状态转变的证明(Merkle state transition proof)。从本质上来讲,这样的证明也就是在说“如果你在根S的状态树上运行交易T,其结果状态树将是根为S’,log为L,输出为O” (“输出”作为存在于以太坊的一种概念,因为每一笔交易都是一个函数调用,它在理论上并不是必要的)。
为了推断这个证明,服务器在本地创建了一个假的区块,将状态设为 S,并假装是一个轻客户端,同时请求这笔交易。也就是说,如果请求这笔交易的过程,需要客户端确定一个账户的余额,这个轻客户端会发出一个余额疑问。如果这个轻客户端需要检查存储在一个特定合约的特定项目,该轻客户端会对此发出针对查询。服务器会正确地“回应”它所有的查询,但服务器也会跟踪它所有发回的数据。然后,服务器会把综合数据发送给客户端。客户端会进行相同的步骤,但会使用它的数据库所提供的证明。如果它的结果和服务器要求的是相同的,那客户端就接受证明。
MPT树可以参考文章Merkle树
3.Bloom
区块头里的布隆过滤器是用于搜索收据而构建的。
挖矿难度控制
1.Difficulty
以太坊的挖矿难度是动态调整的,它的难度调整仅和父区块和本区块挖矿时间有关。 而该函数实现里根据启动参数目前有三种难度调整方案:
1 2 3 4 5 6 7 8 9 10 11 | |
每种策略代码这里不具体展开,总的来说难度值的计算是这样的:
1 2 3 | |
以太坊的区块难度以单个区块为单位进行调整,可以非常迅速的适应算力的变化,正是这种机制,使以太坊在硬分叉出以太坊经典(ETC)以后没有出现比特币分叉出比特币现金(BCC)后的算力“暴击”问题。同时,以太坊的新区块难度在老区块的基础上有限调整的机制也使区块难度不会出现非常大的跳变
从这个公式可以看出,区块难度短期内仅和难度调整值有关(因为难度炸弹只有每100000个区块才会产生跳变),但是当挖矿到5400000区块后,难度值跳变到非常大,这个时候就不再适合挖矿。
PoW参数
接下来的两个参数就和无人不知无人不晓的工作量证明息息相关了,以太坊的工作量证明最终拼的就是谁最先得到这两个参数:MixDigest和Nonce.
目前以太坊线上使用的共识算法是基于PoW的ethash算法,主要实现位于github.com/ethereum/go-ethereum/consensus/ethash包中。
PoW算法的思路都大致是相似的,通过暴力枚举猜测一个nonce值,使得根据这个nonce种子计算出的hash值符合约定的难度,这个难度其实就是要求hash值前缀包含多少个0.
目前以太坊使用的hash是256位,所以将难度折算成前缀0的位数就是:bits0 = (2^256)/difficulty,那么我们的代码不停枚举nonce然后将计算得到的hash值前缀0位数和这个做比较就行了,主逻辑代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
该函数首先计算出区块难度对应的前缀0位数target,然后生成PoW依赖的计算数据集dataset = ethash.dataset(number),最终开始死循环尝试计算digest, result := hashimotoFull(dataset.dataset, hash, nonce),得到结果后将这两个随机数据赋值到区块头对应字段去。
当这个区块成功挖出后,别的区块很容易验证这个区块的PoW是否有效,就使用同样方法产生计算数据集dataset,然后调用hashimotoLight(和hashimotoFull基本一致)计算出digest和区块头的MixDigest做比较就可以了。
这里我们跳过了两个重要的步骤:
a.依赖数据集dataset的生成实现
b.hashimotoFull/hashimotoLight的具体实现
依赖数据集的生成就要说到以太坊的DAG
DAG
ethash将DAG(有向非循环图)用于工作量证明算法,这是为每个epoch(epoch := block / epochLength)生成,例如,每3000个区块(125个小时,大约5.2天)。DAG要花很长时间生成。如果客户端只是按需要生成它,那么在找到新epoch第一个区块之前,每个epoch过渡都要等待很长时间。然而,DAG只取决于区块数量,所以可以预先计算来避免在每个epoch过渡过长的等待时间。Geth和ethminer执行自动的DAG生成,每次维持2个DAG以便epoch过渡流畅。挖矿从控制台操控的时候,自动DAG生成会被打开和关闭。
hashimoto
下面的描述摘自挖矿和共识算法的奥秘
hashimoto()的逻辑比较复杂,包含了多次、多种哈希运算。下面尝试从其中数据结构变化的角度来简单描述之:
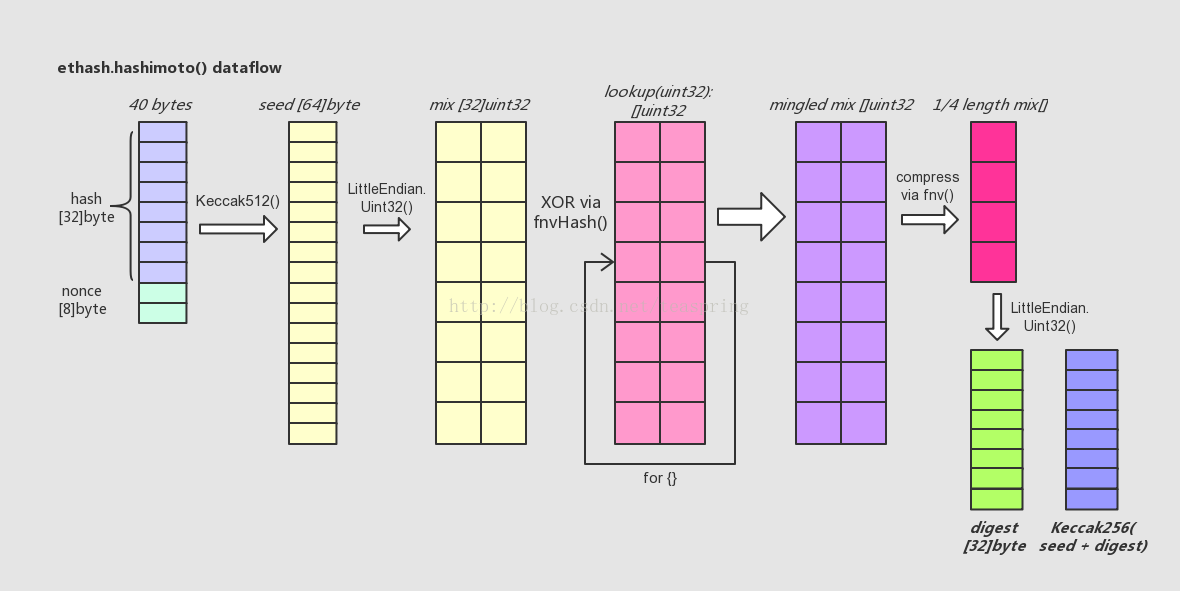
简单介绍一下上图所代表的代码流程:
- 首先,hashimoto()函数将入参@hash和@nonce合并成一个40 bytes长的数组,取它的SHA-512哈希值取名seed,长度为64 bytes。
- 然后,将seed[]转化成以uint32为元素的数组mix[],注意一个uint32数等于4 bytes,故而seed[]只能转化成16个uint32数,而mix[]数组长度32,所以此时mix[]数组前后各半是等值的。
- 接着,lookup()函数登场。用一个循环,不断调用lookup()从外部数据集中取出uint32元素类型数组,向mix[]数组中混入未知的数据。循环的次数可用参数调节,目前设为64次。每次循环中,变化生成参数index,从而使得每次调用lookup()函数取出的数组都各不相同。这里混入数据的方式是一种类似向量“异或”的操作,来自于FNV算法。
- 待混淆数据完成后,得到一个基本上面目全非的mix[],长度为32的uint32数组。这时,将其折叠(压缩)成一个长度缩小成原长1/4的uint32数组,折叠的操作方法还是来自FNV算法。
- 最后,将折叠后的mix[]由长度为8的uint32型数组直接转化成一个长度32的byte数组,这就是返回值@digest;同时将之前的seed[]数组与digest合并再取一次SHA-256哈希值,得到的长度32的byte数组,即返回值@result。
最终经过一系列多次、多种的哈希运算,hashimoto()返回两个长度均为32的byte数组 - digest[]和result[]。回忆一下ethash.mine()函数中,对于hashimotoFull()的两个返回值,会直接以big.int整型数形式比较result和target;如果符合要求,则将digest取SHA3-256的哈希值(256 bits),并存于Header.MixDigest中,待以后Ethash.VerifySeal()可以加以验证。
其他
1.Extra