深入ethereum源码-p2p模块节点发现机制
ethereum是基于kademlia协议实现其节点自动发现机制,完整整个网络拓扑关系的构建刷新。
Kademlia协议
以下内容摘自维基百科,全文查看参考文献Kademlia
Kademlia是一种通过分散式杂凑表实现的协议算法,它是由Petar和David为非集中式P2P计算机网络而设计的。Kademlia规定了网络的结构,也规定了通过节点查询进行信息交换的方式。Kademlia网络节点之间使用UDP进行通讯。参与通讯的所有节点形成一张虚拟网(或者叫做覆盖网)。这些节点通过一组数字(或称为节点ID)来进行身份标识。节点ID不仅可以用来做身份标识,还可以用来进行值定位。
Kademlia路由表由多个列表组成,每个列表对应节点ID的一位(例如:假如节点ID共有128位,则节点的路由表将包含128个列表),包含多个条目,条目中包含定位其他节点所必要的一些数据。列表条目中的这些数据通常是由其他节点的IP地址,端口和节点ID组成。每个列表对应于与节点相距特定范围距离的一些节点,节点的第n个列表中所找到的节点的第n位与该节点的第n位肯定不同,而前n-1位相同,这就意味着很容易使用网络中远离该节点的一半节点来填充第一个列表(第一位不同的节点最多有一半),而用网络中四分之一的节点来填充第二个列表(比第一个列表中的那些节点离该节点更近一位),依次类推。如果ID有128个二进制位,则网络中的每个节点按照不同的异或距离把其他所有的节点分成了128类,ID的每一位对应于其中的一类。随着网络中的节点被某节点发现,它们被逐步加入到该节点的相应的列表中,这个过程中包括向节点列表中存信息和从节点列表中取信息的操作,甚至还包括当时协助其他节点寻找相应键对应值的操作。这个过程中发现的所有节点都将被加入到节点的列表之中,因此节点对整个网络的感知是动态的,这使得网络一直保持着频繁地更新,增强了抵御错误和攻击的能力。
在Kademlia相关的论文中,列表也称为K桶,其中K是一个系统变量,如20,每一个K桶是一个最多包含K个条目的列表,也就是说,网络中所有节点的一个列表(对应于某一位,与该节点相距一个特定的距离)最多包含20个节点。随着对应的bit位变低(即对应的异或距离越来越短),K桶包含的可能节点数迅速下降(这是由于K桶对应的异或距离越近,节点数越少),因此,对应于更低bit位的K桶显然包含网络中所有相关部分的节点。由于网络中节点的实际数量远远小于可能ID号的数量,所以对应那些短距离的某些K桶可能一直是空的(如果异或距离只有1,可能的数量就最大只能为1,这个异或距离为1的节点如果没有发现,则对应于异或距离为1的K桶则是空的)。

让我们看上面的那个简单网络,该网络最大可有2^3,即8个关键字和节点,目前共有7个节点加入,每个节点用一个小圈表示(在树的底部)。我们考虑那个用黑圈标注的节点6,它共有3个K桶,节点0,1和2(二进制表示为000,001和010)是第一个K桶的候选节点,节点3目前(二进制表示为011)还没有加入网络,节点4和节点5(二进制表示分别为100和101)是第二个K桶的候选节点,只有节点7(二进制表示为111)是第3个K桶的候选节点。图中,3个K桶都用灰色圈表示,假如K桶的大小(即K值)是2,那么第一个K桶只能包含3个节点中的2个。众所周知,那些长时间在线连接的节点未来长时间在线的可能性更大,基于这种静态统计分布的规律,Kademlia选择把那些长时间在线的节点存入K桶,这一方法增长了未来某一时刻有效节点的数量,同时也提供了更为稳定的网络。当某个K桶已满,而又发现了相应于该桶的新节点的时候,那么,就首先检查K桶中最早访问的节点,假如该节点仍然存活,那么新节点就被安排到一个附属列表中(作为一个替代缓存).只有当K桶中的某个节点停止响应的时候,替代cache才被使用。换句话说,新发现的节点只有在老的节点消失后才被使用。
以太坊Kademlia-like协议
以太坊的kademlia网(简称kad)和标准kad网有部分差异.
下面对照以太坊源码,阐述下kad网里几个概念:
1 2 3 4 5 6 | |
α即代码里的alpha,是系统内一个优化参数,控制每次从K桶最多取出节点个数,ethereum取值3bucketSize,K桶大小,ethereum取16hashBits,节点长度256位nBuckets,K桶个数,目前取257
以太坊Kad网总共定义了4种消息类型:
1 2 3 4 5 6 7 | |
ping和pong是一对操作,用于检测节点活性,节点收到ping消息后立即回复pong响应:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
findnode和neighbors是一对操作.
findnode用于查找与某节点相距最近的节点,查找到后以neighbors类型消息回复查找发起者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
源码跟踪以太坊节点发现机制
了解了以太坊的4种基本操作以及kad网络概念,我们就可以来看看节点发现机制怎么流转起来的:
节点发现的代码位于github.com/ethereum/go-ethereum/p2p/discover包。
首先,在节点启动时启动UDP”端口监听”:server.Start() ==> discover.ListenUDP ==> newUDP()
newUDP()分叉出去三个流程,三个流程均是无限循环:
func (tab *Table) refreshLoop()func (t *udp) loop()func (t *udp) readLoop(unhandled chan ReadPacket)
1. refreshLoop()
该流程每隔1小时或按需刷新K桶,核心逻辑实现位于doRefresh函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
tab.lookup函数虽然关键,然而其逻辑其实是很简单的:
a. 查询离target最近一批节点,距离计算即对kad网络XOR(异或)距离计算的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
b. 迭代上一步查到的所有节点,向这些节点发起findnode操作查询离target节点最近的节点列表,将查询得到的节点进行ping-pong测试,将测试通过的节点落库保存
经过这个流程后,节点的K桶就能够比较均匀地将不同网络节点更新到本地K桶中。
2. loop()和readLoop()
这两个循环流程放在一起说,它们主要是一个工程实现,将异步调用代码通过channel串接成同步。业务上主要是负责处理ping,pong,findnode,neighbors四个消息类型的收发。
唯一值得稍加阐述的可能只有pending结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
综述,邻居节点发现流程:
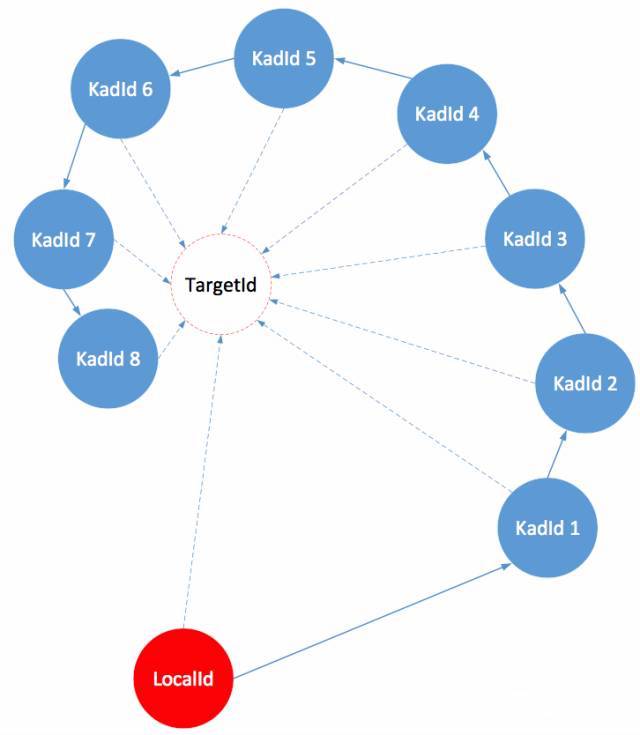
节点第一次启动读取公共种子节点信息,已本节点ID作为target更新本地K桶,然后每隔一段时间进行节点更新, 刷新K桶流程如下:
a. 随机生成目标节点Id,记为TargetId,从1开始记录发现次数和刷新时间。
b. 在当前节点的K桶里查找与目标节点最近的16个节点
c. 向b中得到的每个节点发送findnode命令,接收到每个节点传回的neighbours节点
d. 对c返回的每个节点进行ping-pong测试然后更新到本地k桶
e. 上述流程均是基于UDP的发现流程,p2p网络会定时随机取k桶中未连接的节点进行TCP连接,在连接好的TCP通道进行通信(tcp连接协程里会自己做心跳维护这个连接)
内网穿透
ethereum是基于p2p通信的,所有的操作都有可能涉及到内网穿透,而目前内网穿透最常用的方法是udp打洞,这也是kad网络使用udp作为基础通信协议的原因。
一个简单的udp打通进行p2p通信的例子讲解可以参考深入ethereum源码-p2p模块基础结构。
然而以太坊里将这部分逻辑全部隐藏,可以在节点初始化函数里看出一点痕迹:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
首先,以太坊tcp/udp共用了一个端口,然后使用uPnp协议簇进行内外网端口映射,完成链路打通,从而穿透内网.
具体封装位于nat模块,但具体实现也是使用了三方库goupnp.具体实现是关于uPnP的一个大话题,就不在这里分叉出去了。